JDBC経由でAurora MySQLに接続できない
おはこんばんにちは、ビショップです。
AWS Aurora MySQLに同じくAWSのEC2上のアプリケーションからJDBC経由でMySQLに接続できなくて困る、という事案が発生しました。
環境はこんな感じ。
- AWS Aurora MySQL(5.7.mysql_aurora.2.10.2)
- AWS EC2 RHEL 8.4
- mysql-connector-java-8.0.15.jar
- java 17
普通にMySQLコマンドで接続すれば接続できるのが肝です。
結論からいうと、TLSのバージョンの問題のようです。
いつのころから、JavaのTLSのデフォルトがTLS1.3になったみたいですね。
TLS1.2でつなぎましょう。
JDBCの接続文字列に下記オプションを付けます。
enabledTLSProtocols=TLSv1.2
こんな感じになります。
jdbc:mysql://endpoint_name/dbname?enabledTLSProtocols=TLSv1.2
やったー、つながったー。
【Zabbix】ホストインベントリ一覧の表示カラムをカスタマイズする
おはこんばんにちは、ビショップです。
久々の記事は備忘録。
最近Zabbixをからかってます。会社で運用する上で色々と体系化しておかないといけないので、勤め先の要件に合うような形でガイドラインを作成しています。そんな中で、ちょっとカスタマイズしたいなというところがあったので、そのやり方を備忘録として書いておこうかなと。
やりたいこと
Zabbixのホストインベントリの一覧に表示されているカラムを変更したい。拠点が多いので、場所とかそういうインベントリ情報を出していきたいなと。
ホストインベントリページのソースは/usr/share/zabbix/hostinventories.phpです。リスト自体は、ソースコード内にも記述されていますが、/usr/share/zabbix/include/views/inventory.host.list.phpで生成されているようです。というわけで、この2つのソースをカスタマイズしていきます。
今回の条件としては、以下とします。
- Zabbix 5.0
- 追加する項目は「備考」
- ソートもちゃんと設定する
項目の追記にはちゃんとしたZabbix上での正しいフィールド名が必要です。テーブルのカラム名なんだと思いますが、マニュアルにある、サポートされているマクロのインベントリの説明を見れば分かるので、参考にしてください。「備考」は「notes」です。
では、実際にカスタマイズしていきましょう。
※ソースコードはシンタックスハイライトの関係で?phpが最初に書いてあります。
hostinventories.phpのカスタマイズ
ソート用フィールドの追加
だいたい39行目くらいから各フィールドの設定が記述されているので、その中のソートの部分に追記します。他にならって”pr_notes”というソートフィールドを追記します。
<?php $fields = [ 'hostid' => [T_ZBX_INT, O_OPT, P_SYS, DB_ID, null], // filter 'filter_set' => [T_ZBX_STR, O_OPT, P_SYS, null, null], 'filter_rst' => [T_ZBX_STR, O_OPT, P_SYS, null, null], 'filter_field' => [T_ZBX_STR, O_OPT, null, null, null], 'filter_field_value' => [T_ZBX_STR, O_OPT, null, null, null], 'filter_exact' => [T_ZBX_INT, O_OPT, null, 'IN(0,1)', null], 'filter_groups' => [T_ZBX_INT, O_OPT, null, DB_ID, null], // actions 'cancel' => [T_ZBX_STR, O_OPT, P_SYS, null, null], // sort and sortorder 'sort' => [T_ZBX_STR, O_OPT, P_SYS, // ここに追記 //IN('"name","pr_macaddress_a","pr_name","pr_os","pr_serialno_a","pr_tag","pr_type"'), IN('"name","pr_macaddress_a","pr_name","pr_os","pr_serialno_a","pr_tag","pr_type","pr_notes"'), null ], 'sortorder' => [T_ZBX_STR, O_OPT, P_SYS, IN('"'.ZBX_SORT_DOWN.'","'.ZBX_SORT_UP.'"'), null] ];
インベントリデータ取得用のフィールド追加
実際のインベントリデータの取得に使うフィールドを指定してるっぽいところに追記します。
だいたい200行目くらいのところからインベントリデータの取得設定があり、その中の'selectInventory'の中を変更します。
<?php $options = [ // 201行目くらい 'output' => ['hostid', 'name', 'status'], // ここに追記 //'selectInventory' => ['name', 'type', 'os', 'serialno_a', 'tag', 'macaddress_a', $data['filter']['field']], 'selectInventory' => ['name', 'type', 'os', 'serialno_a', 'tag', 'macaddress_a', 'notes', $data['filter']['field']], 'selectGroups' => API_OUTPUT_EXTEND, 'groupids' => $filter_groupids, 'filter' => ['inventory_mode' => [HOST_INVENTORY_MANUAL, HOST_INVENTORY_AUTOMATIC]] ];
しっかりシングルコーテーションでくくり、カンマを付けましょう。
値設定の追記
ソート用フィールドの値設定に追記します。だいたい230行目くらいにあります。
<?php $sort_fields = [ 'pr_name' => 'name', 'pr_type' => 'type', 'pr_os' => 'os', 'pr_serialno_a' => 'serialno_a', 'pr_tag' => 'tag', 'pr_macaddress_a' => 'macaddress_a', // 追記 直前のカンマ追記など忘れずに 'pr_notes' => 'notes' ];
これでhostinventories.phpの編集は完了です。上書き保存しましょう。
inventory.host.list.phpのカスタマイズ
実際にリストを生成してくれるところをカスタマイズしていきましょう。やることはヘッダー部分の追記と繰り返し値をセットする部分の項目追記になります。
ヘッダーへ追記
80行目くらいのところにヘッダー処理がありますので、そこに追記します。ソート機能をちゃんとつけたいので、make_sorting_headerとなっている項目を参考に追記しましょう。
<?php $table = (new CTableInfo()) ->setHeader([ make_sorting_header(_('Host'), 'name', $this->data['sort'], $this->data['sortorder'], $url), _('Group'), make_sorting_header(_('Name'), 'pr_name', $this->data['sort'], $this->data['sortorder'], $url), make_sorting_header(_('Type'), 'pr_type', $this->data['sort'], $this->data['sortorder'], $url), make_sorting_header(_('OS'), 'pr_os', $this->data['sort'], $this->data['sortorder'], $url), make_sorting_header(_('Serial number A'), 'pr_serialno_a', $this->data['sort'], $this->data['sortorder'], $url), make_sorting_header(_('Tag'), 'pr_tag', $this->data['sort'], $this->data['sortorder'], $url), make_sorting_header(_('MAC address A'), 'pr_macaddress_a', $this->data['sort'], $this->data['sortorder'], $url), // 追記 make_sorting_header(_('Notes'), 'pr_notes', $this->data['sort'], $this->data['sortorder'], $url) ]);
繰り返し処理に追記
100行目くらいのところに繰り返し処理のうち、行の設定部分が記述されています。そこに追記します。他のカラムの情報をコピペしましょう。今までもそうですが、最後尾に追加する場合は、その前の項目にカンマを付ける場合があるので、気を付けましょう。ここはカンマもちゃんと追記します。
<?php $row = [ (new CLink($host['name'], (new CUrl('hostinventories.php'))->setArgument('hostid', $host['hostid']))) ->addClass($host['status'] == HOST_STATUS_NOT_MONITORED ? ZBX_STYLE_RED : null), $hostGroups, zbx_str2links($host['inventory']['name']), zbx_str2links($host['inventory']['type']), zbx_str2links($host['inventory']['os']), zbx_str2links($host['inventory']['serialno_a']), zbx_str2links($host['inventory']['tag']), zbx_str2links($host['inventory']['macaddress_a']), // 追記 前の行にカンマを忘れずに zbx_str2links($host['inventory']['notes']) ];
これでinventory.host.list.phpの編集も完了しました。上書き保存して、Zabbixのページを再度見てみましょう。

イェーイ、項目追加されたー!参考画像は、初期表示の「OS」を「場所(location)」に変更してあります。これで必要な項目を表示してホストの管理しやすくできます。
ホントは別の機器管理の台帳があるので、そこと二重管理になってしまうのがネックですね。連携するようにしちゃおうかな。趣味の範囲だけど。
レビュー【山善 スチームキューブ】シンプルイズベスト!?最強の象印加湿器に勝てるか!
おはこんばんにちは、ビショップです。
みなさん、この冬はいかがお過ごし?寒さに磨きがかかって、大分乾燥してますね。コロナ禍の中、お部屋の乾燥も気になるお年頃に私もなりました。我が家では、以前から、加湿機能付き空気清浄機をリビング用、使い勝手・性能から最強と呼び声高い象印さんの見た目がほぼポットの乾燥機を寝室用に使っていましたが、昨年、本格的な冬に入る前に1つ加湿器を買い足しました。リビング用の加湿機能付き空気清浄機ですが、ちょっと加湿感弱かったんです。妻がもう少し加湿したいとのことで、リビングの補佐にそこそこの性能で良い感じの価格、手入れしやすいものを探して購入しました。今日はその加湿器を紹介しようかと思います。
今回ご紹介する商品はこちら。
![[山善] 加湿器 加熱式 スチーム式 上部給水方式 (最大加湿 600ml) (タンク容量2.8L) (木造約10畳/プレハブ洋室約17畳) (着脱式タンク) ホワイト KSF-K283(W) [メーカー保証1年]](https://m.media-amazon.com/images/I/311t1MPnUmL._SL500_.jpg "[山善] 加湿器 加熱式 スチーム式 上部給水方式 (最大加湿 600ml) (タンク容量2.8L) (木造約10畳/プレハブ洋室約17畳) (着脱式タンク) ホワイト KSF-K283(W) [メーカー保証1年]")
山善さんの”SteamCUBE”(スチームキューブ)です。
公式HPはこちら
book.yamazen.co.jp
商品概要
公式スペックでいうと…
- 加湿範囲:木造10畳
- タンク容量:約2.8L
- 連続稼働時間:標準約7時間
- 上部給水式
箱の外観はこんな感じ。

開けて内容物はこんな感じ。シンプル。

蓋がバカっと開きます。


この加湿器の良いところは、タンクが取り外し可能なところ。

実際の使用感
加湿性能
文句なし!我が家はリビングとキッチン合わせて15畳くらいになるんですが、2台体制でしっかり加湿してくれてると思います。なんなら加湿機能付き空気清浄機よりスチームキューブの方がちゃんと加湿してくれてるくらいです。スチームキューブなしでは湿度40数%にしかなりませんが、スチームキューブありで60数%まで上げてくれます。
お手入れ
タンクを外して洗えるって周りに気兼ねしなくてめっちゃいいです。本体への水はねを気にしなくでいいのでガシガシ洗えます。フッ素加工してあるので、やさしくですけど。我が家ではそのまま水を入れてセットしちゃってます。危ないのでマネしないでください。
他機能
自動停止機能あります。安心。ボタン1つでon/off、コースの切り替えもできる。シンプル。
まとめ
以上です。なんの不足があろうか。シンプルイズベスト。そりゃぁ象印さんのはチャイルドロックもあるし、クエン酸洗浄モードもあるし、湯沸かし音セーブモードもあるし、マジで最強なんですけど、安全なところに置いて、とりあえず湿度上げたいっていう場合、こっちも良いんじゃないでしょうか。価格は1万円しないので、とりあえず迷っていたら山善さんのSteamCUBE、いかがでしょうか。
ちなみに、上位機種?で、タイマーやチャイルドロックのついた機能の多いものもあるので、検討してみてもいいんじゃないでしょうか。こちらも同じようにタンクが外れるのでお手入れ感は一緒だと思います。こちらはCUBE感ないなぁ…。
![[山善] スチームファン式 加熱式 加湿器 上部給水式 (湿度センサー搭載) (最大加湿 600ml) (タンク容量 3.0L) (木造約10畳/プレハブ洋室約17畳) (タイマー 最大4時間) (チャイルドロック) (着脱式タンク) (メモリー機能) ホワイト KSF-L301(W) [メーカー保証1年]](https://m.media-amazon.com/images/I/31UbmrIzQBL._SL500_.jpg "[山善] スチームファン式 加熱式 加湿器 上部給水式 (湿度センサー搭載) (最大加湿 600ml) (タンク容量 3.0L) (木造約10畳/プレハブ洋室約17畳) (タイマー 最大4時間) (チャイルドロック) (着脱式タンク) (メモリー機能) ホワイト KSF-L301(W) [メーカー保証1年]")
【誰得】SVNのリポジトリがWindowsファイル共有だけどアプリはLinuxで動かしたい
おはこんばんにちは、ビショップです。
タイトル的に何を言ってるか分からないと思いますし、私も何を言ってるか分からないところがありますが、まず状況から整理します。
- Subversionでソースを管理している
- サーバから何から何までWindows環境になっているような環境
- svnリポジトリがWindowsファイル共有。apacheと連携してたりはしない
- リポジトリへのアクセスは”file://server/repo”みたいな感じ
地獄のような環境ですね。いや、Windows環境なら単純っちゃ単純な設定なんでしょうか。どうしてこうなっているのか、全然分からないんですが、今回はこの環境を以下のようにしていこうと試行錯誤したまとめです。
- テストでアプリケーションを稼働させるテスト環境サーバのOSをLinux(RHEL)にする
- ソースは既存Windowsファイル共有のリポジトリからチェックアウトしたりコミットしたりアップデートしたりできるようにする
誰も得しない記事ですが、張り切ってまとめました。
問題点
SVNのリポジトリがWindowsファイル共有ということで、普通にsvnコマンドでリポジトリへアクセスしようとしてもダメです。なにがしかのエラーになります。
[root@server /]# svn ls svn://serverIP/repo/ svn: E170013: Unable to connect to a repository at URL 'svn://serverIP/repo' svn: E000111: Can't connect to host 'serverIP': Connection refused [root@server /]# svn ls file:///serverIP/repo/ svn: E170013: Unable to connect to a repository at URL 'file:///serverIP/repo' svn: E180001: Unable to open repository 'file:///serverIP/repo'
アクセスできないので論外ですね。
解決方法
分かっていましたが、ファイル共有としてアクセスできなきゃダメなんです。そう、マウントしましょう。
前提として、Subveresion、cifs-utilsは導入済みです。
Windows側の準備
共有フォルダにアクセスできる専用ユーザをローカルに作ります。このユーザをLinuxでのマウント時に指定します。例として、ユーザ名は”svn_user”、パスワードは”svn_pw”とします。
とりあえずマウント用フォルダを作る
[root@server /] mkdir /svn
マウント
[root@server /] mount -t cifs -o user=svn_user,password=svn_pw //serverIP/repo /svn/
SVNで見れるか確認
[root@server /] svn ls file:///svn/repo test/ test2/
はい勝った。
好きなところでチェックアウトしたり、コミットしたり、アップデートしたりしてください。いや、誰もやらないか…
一応、Linuxでfile://を使う場合、スラッシュは3本(file:///)です。気をつけましょう。
PowerQueryのプライバシーレベルについて完全に理解した
おはこんばんにちは、ビショップです。
最近PowerQuery for Excelってのが社内で話題です。私もなんか使い方を勉強してますけども、今回はその使い方ではなく、おそらく誰しもよく分からずに使ってしまっているであろう、データソースの「プライバシーレベル」について、設定によってどんな動きになるか調査・検証してみました。
プライバシーレベル自体は、データソースごとに設定するもので、そのデータソース自体がどの程度の機密性を持つかを指定するものだという認識で良いと思います。異なる2つのデータソース間で検索条件等をやり取りする場合に、設定したレベルによって、データの取り扱い方が変わります。レベルは3つ設定できますが、Microsoftのヘルプは相変わらずよく分からないので、実際に設定してどういった動きになるか見てみましょう。
設定できるプライバシーレベルは以下の3つです。
- プライベート
- 組織
- パブリック
データの取り扱いとは
ExcelにPowerQueryで、データソースAとデータソースBを設定しているとします。データソースAが例えばマスタで、その情報をキーにデータソースBのデータを抽出するクエリを作成したとします。その場合、データの絞り込みには2つの方法があります。
- データソースAのキーをデータソースBに渡して、データソースBで絞り込みを実行した結果をExcelに返す
- データソースBの全データをとりあえず持ってきて、Excel上でデータソースAのキーを使ってフィルタをかける
何が問題なのか
1の方法では、データソースBに検索条件付きのSQLを投げます。つまり、SQLのログがDBMS側に残ってしまいます。分かる人なら検索条件、抽出できてしまいますね。それが顧客情報に関するものだったりするとまずいですね。データの保存先によりますが、もしかしたら情報漏洩になったりするかもしれません。
2の方法では、1の方法と違い、ローカルに全データを持ってきてから処理します。重そうですね。でも余計な情報を外に漏らすことはなさそうです。
この制御というかリスク回避をプライバシーレベルの設定でなんとかするということのようです。
実際の動作
データソースAをパラメータとして扱い、データソースBを絞り込んで表示します。この時のデータソースAのプライバシーレベルによる動作の違いです。データソースAを入力パラメータ、データソースBをSQLServer内のトランザクションデータとし、SQLServerの実行SQLがどうなるか検証しました。

パブリック
「パブリック」に設定した入力パラメータは、データソースBに対して発行されるSQLに検索条件が付与されて実行されます。これは相手のプライバシーレベルは関係ありません。上記画像のようなパラメータの入力がされていた場合、SQLServer側で実行されるSQLはこうなります。
SELECT * FROM table WHERE customer = 'AAAA'
プライベート
「プライベート」に設定したデータソースは一番機密性の高いデータとして扱われ、他のデータソースに一切データ送信されません。SQL文は一切検索条件が付与されないシンプルなものが発行されます。データソースAをプライベートとした場合、どんな入力をしていたとしてもSQLServer側で実行されるSQLはこうなります。
SELECT * FROM table
組織
「組織」に設定したデータソースは、検索に行く相手データソースが「組織」だった場合とそれ以外だった場合で動作が変わります。相手も「組織」だった場合は、パブリックと同様の動作になり、このSQLが実行されます。
SELECT * FROM table WHERE customer = 'AAAA'
相手がパブリックだったりプライベートだったりした場合は、全件検索するSQLが実行されます。
SELECT * FROM table
実際どうすべき?
社内データしか扱わない、ということが分かっていれば「組織」でいいですね。でも基本は「プライベート」を案内する方がいいでしょう。ちゃんと理解してくれる人がいればちゃんと教えるんですが、こういうの理解してくれる人ってあんまりいないのが常ですよねぇ。
【神機能】VSCodeからいろんなDBを使う【自己責任】
おはこんばんにちは、ビショップです。
前回、前々回とVisualStudio CodeからMySQLやMS SQLServerに接続していろいろできる拡張機能を紹介してきました。
今回は、1つの拡張機能でMySQLやMS SQLServerに加え、PostgreSQLやMongoDB、さらにはFTP接続までできるというものを紹介します。
なお、日本語情報は少ないので、追加は自己責任でお願いします。GitHubやマケプレを見る限りは、どちゃくそ評価が高く、懸念点はMITライセンスなのでそれこそ自己責任ってことくらいですかね。
今回ご紹介する拡張機能はこちら。

全く同じ機能で「MySQL」という名称の拡張機能がありますが、同じ作者さんなので、プロジェクト作り直したんでしょうね。リリース日は「Database Client」の方が新しくなっています。
インストール
拡張機能の検索ボックスから検索してインストールしましょう。インストールすると下画像のようなアイコンがアクティビティバーに表示されます。
コネクションの追加
早速DBコネクションを追加してみようと思います。アクティビティバーに表示されたDBアイコンをクリックしてサイドバーを切り替えます。表示された「DATABASE」の横にある「+」マークをクリックしてコネクションの設定画面を開きます。

コネクションの設定はコマンドパレットではなく、エディタにGUIの設定画面が出てきます。便利。下の画像はMySQLの設定画面ですね。画面中段にある、「Server Type」のすぐ下がタブになっているので、そちらでDBの種類を切り替えることができます。

PostgreSQLや…
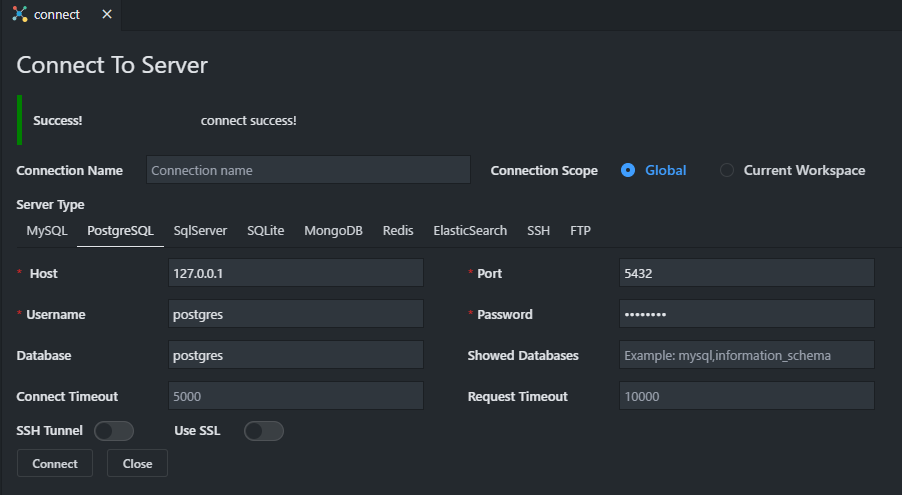
SQLServerなど、いろいろ選択できます。

正しく接続情報を入力して「Connect」ボタンをクリックするとサイドバーにDBの情報が表示されます。DBに合わせたアイコンが表示されるんですね。いい感じ。

ちなみに、SSHやFTPコネクションを追加した場合は、NoSQLのサイドバーに表示されます。

テーブルの参照
データベース名をクリックするとテーブルやビュー、プロシージャといった階層が展開されます。
さらにTableを展開すると、データベース内のテーブル一覧が展開されます。

テーブルをクリックすればテーブルの情報を参照できます。この参照画面で大体の設計情報含め十分な情報が確認できます。権限があればこの画面からデータ編集もできてしまうのでその辺は注意しましょう。直感的に操作できるような洗練されたUIになので、特に詳しい説明は省きます。

テーブルの設計
サイドバーのテーブルを右クリックして「Design Table」で設計情報を詳しく参照できます。当然変更もできます。

設計画面は下画像のような感じですが、使いやすさで言うと、編集には画面右側のOperationというところから編集画面を別に開く必要があるので、毎回は面倒かなって感じです。テーブル作成時にはCreate文でやっちゃうことが多いので、ちょっとした変更の時くらいしか使わないと思いますが…
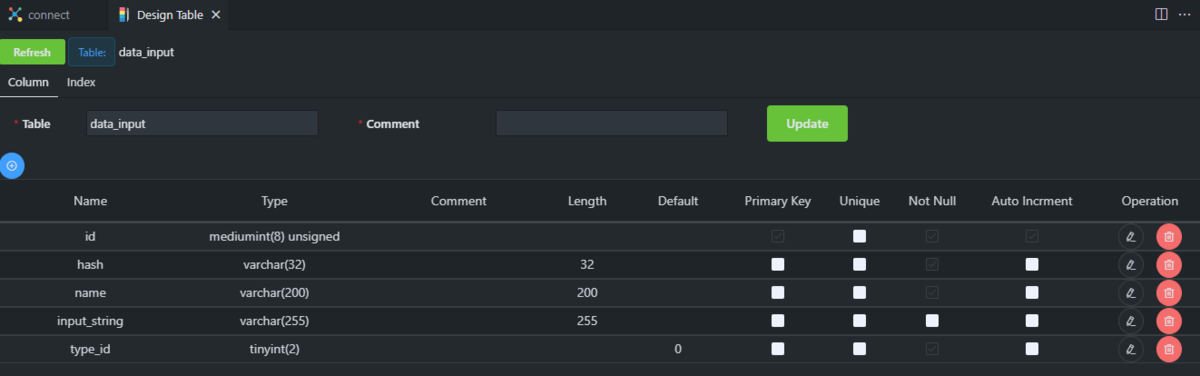
ちなみに変更すると特に断りなく勝手に保存されるのでジャンジャン設計内容が更新されます。

クエリの実行
クエリは実行したいデータベース名の右側に出てくる「Open Query」から実行します。
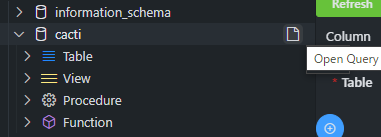
エディタにクエリが開くので、SQL文を書いて、「Ctrl+Enter」で実行します。

実行結果はウィンドウが分割して表示されます。

便利機能
サーバステータス
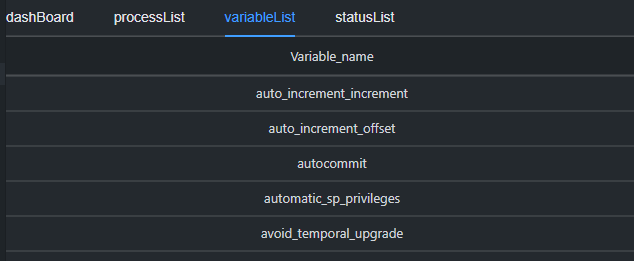
地味に便利な機能として、サーバ名を右クリックして「Server Status」を選択するとプロセスや設定値などのサーバステータスを見ることができます。

processListで現在のプロセスの一覧、MySQLならvariableListで設定値をみることができます。
サイドバーでの検索
マケプレの概要でも動画で紹介されていますが、サイドバー上でのフィルタが生きてるので、たくさんテーブルがある場合は便利ですね。
まとめ
VisualStudio Codeの神拡張機能「Database Client」の紹介でした。データのダウンロードやSQLのエクスポート機能もあるので、ほとんどVSCode上で作業が完結できます。他の拡張機能と同様に、権限管理などは当然専用ソフトに軍配が上がりますが、通常の開発時などのデータ参照や設計変更はこの拡張機能で十分ですね。神機能といって良いんじゃないでしょうか。とはいえ、重ねてになりますが、こちら公式ではないので、拡張機能のインストールは自己責任でお願いします。
【神機能その2】VSCodeからSQL Serverを使う
おはこんばんにちは、ビショップです。
前回、Visual Studio Codeの拡張機能でVSCode上でMySQLを触る機能を紹介しました。今回は、Microsoft SQL Serverを管理できる公式の拡張機能を設定していきたいと思います。
前回の記事はこちら
bishop.hatenadiary.com
拡張機能のインストール
まずは拡張機能をインストールしましょう。拡張機能の検索で、「mssql」と入力して出てくる「SQL Server (mssql)」をインストールします。Microsoftが出している公式の拡張機能です。

インストールすれば機能は有効になりますが、一応再起動しておきましょう。機能が有効になっていれば、アクティビティバーにアイコンが追加されると思います。なければCtrl+Alt+Dのショートカットキーを押してみましょう。

コネクションの追加
さっそくコネクションを追加してみます。初めての場合はサイドバーのCONNECTIONSの下にある「Add Connection」をクリックします。2回目以降は2つ方法があります。
- CONNECTIONSの横に「+」マークが出てるのでそれをクリック
- コマンドパレットからMS SQLのコマンドを検索してAdd Connection
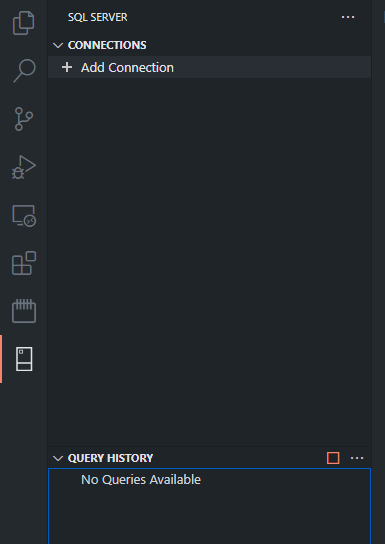
コネクションの追加はコマンドパレット上でやります。まずは接続先のサーバ名です。

デフォルトで接続するDB名。未入力でもOK。

接続の認証方法。今回はSQLServerに作ってあるユーザでログインを試してみるので、SQL Loginを選択。

ユーザ。管理者ならSAとか。

パスワード。

パスワードを保存するかどうか。

プロファイルの名前。

コネクションの作成完了!先ほどつけたプロファイル名がコネクションの一覧に表示されていますね。サーバアイコンのインジケータが緑になっていれば接続できています。
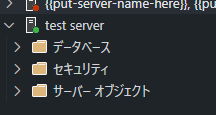
さすが公式なだけあって、テーブルの一覧もそうですが、セキュリティやサーバオブジェクトまで確認できますね。

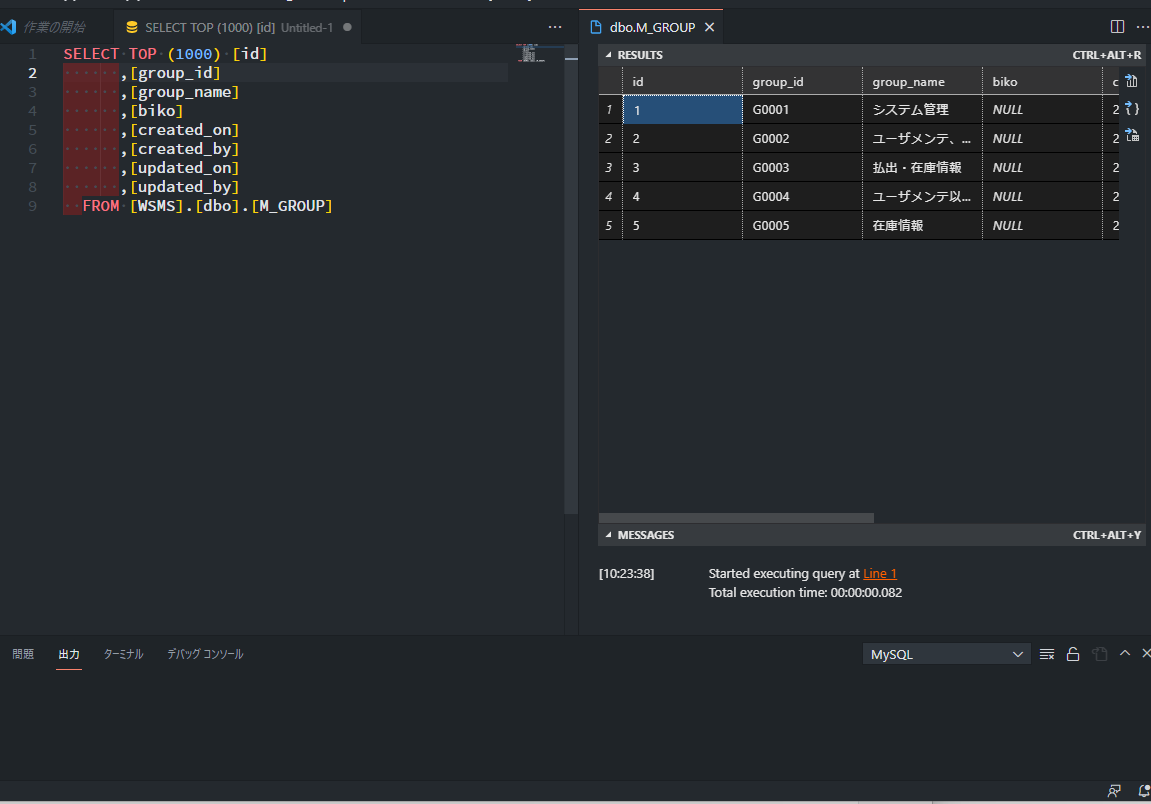
テーブルを右クリックして「Select Top 1000」を実行してみました。さすが公式。洗練されてる。
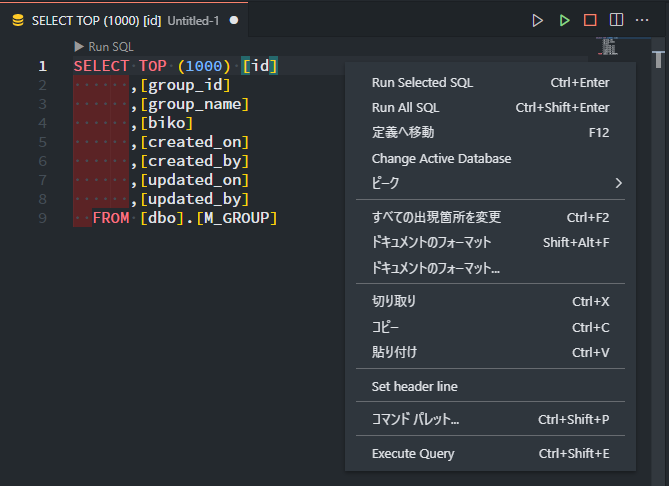
SQLの実行
SQLの実行は、エディタを右クリックして「Execute Query」で。ショートカットは「Ctrl+Shift+E」です。エディタ右上の緑色の再生ボタンでも実行できます。
まとめ
実際に触ってみて、動作も軽快だし、データのチェックや編集とか十分すぎますね。これもうManagement Studio要らないのでは?いや、ちゃんと管理しようと思ったらManagementStudio必要なんですが。普段使いでのレスポンスの良さはこちらの方が良いんじゃないでしょうか。
SQLServerを普段から使っていて、ManagementStudio開くの遅いし、なんかいいツールないかなって人はぜひこの拡張機能試してみてほしいですね。公式っスから。